生成图像这件事宝利配资,会推理的 AI 才是好 AI。
举个例子,以往要是给 AI 一句这样的 Prompt:
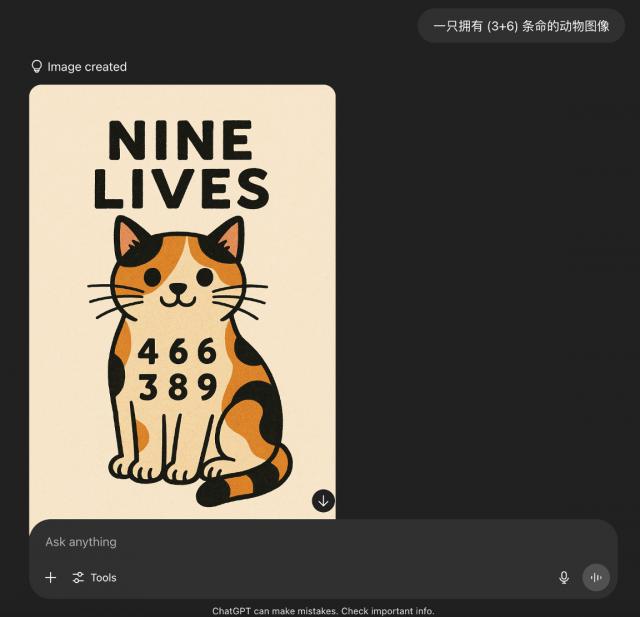
(3+6)条命的动物。
我们人类肯定一眼就知道是猫咪,但 AI 的思考过程却是这样的:

△虽然生成了猫,但思考过程不对
思考的过程还是把"(3+6)"里的数字分开来处理,并没有真正 get 到其背后"九条命的动物 = 猫"的本意。
以及像 ChatGPT,还是执着于在图片里面展示数字:
究其原因,是因为当前主流的基于文本进行图像生成的方法往往依赖固定的文本编码器,仅能处理"纯文本"输入,难以自然接入图像、音频等模态的信息。
同时,这类系统在应对"复杂世界知识"和"多步骤逻辑推理"方面表现乏力。
但就在最近,清华大学、腾讯 ARC Lab、香港中文大学和香港大学联手提出了一个新大模型——MindOmni,显著增强了 AI 的"推理生成能力"。

它不仅能理解复杂指令,还能基于图文内容展开连贯而可信的"思维链"(Chain-of-Thought, CoT),生成具备逻辑性与语义一致性的图像或文本输出:

△推理图像生成可视化结果对比
那么 MindOmni 又是如何做到的呢?
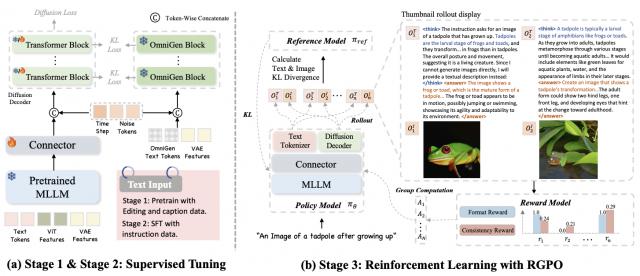
深挖 MindOmni 模型架构
MindOmni 的架构设计的目的比较清晰,就是为了高效融合视觉理解和生成能力。
其大模型部分基于 Qwen2.5-VL 构建,这是一个先进的视觉语言模型,能够处理图像和文本输入。
它通过预训练的 ViT(Vision Transformer)提取图像特征,并将文本编码为离散的标记序列。这种设计使得模型能够理解图像内容并生成与之相关的文本描述。
扩散解码器是 MindOmni 生成图像的核心模块宝利配资。
它基于 OmniGen 构建,通过去噪过程将潜在的噪声信号逐步转化为真实的图像。与传统的生成模型相比,OmniGen 具有更高的灵活性和生成质量。
在生成过程中,模型会将视觉和文本特征与噪声标记在序列维度进行合并,并通过多次去噪循环生成最终的图像。
为了将视觉语言模型与生成模块有效连接,MindOmni 使用一个包含两个标准 Transformer 层的连接器来连接两个模块,并用于对齐 VLM 输出的特征与生成模块的输入维度。
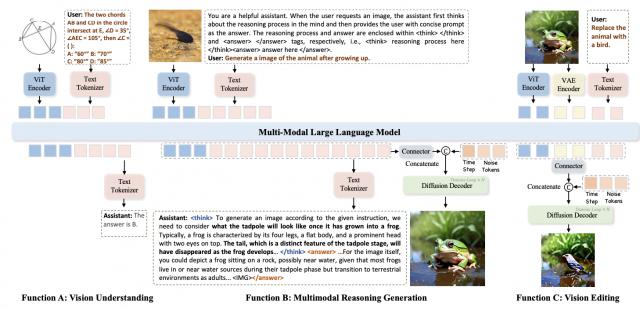
△推理框架概述:MindOmni 在统一的大型模型中完成视觉理解、多模态推理生成和视觉编辑任务三阶段训练流程:从理解到生成的飞跃
MindOmni 采用了三阶段训练策略,以逐步提升模型的性能和推理生成能力。
第一阶段:基础预训练
在预训练阶段,MindOmni 主要利用开源图像 - 文本对和 X2I 数据对来训练连接器。这一阶段的目标是让模型初步具备基本的文本到图像生成能力。
通过扩散损失和基于 KL 散度的蒸馏损失作为优化目标,模型能够学习到图像和文本之间的语义对齐关系。
具体来说,模型会通过采样噪声数据并计算扩散损失来优化生成过程,同时利用 KL 散度来保持与教师模型的一致性。
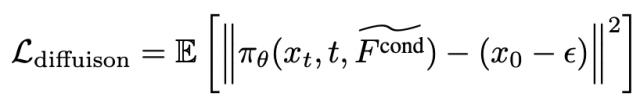
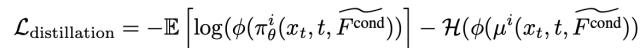
第二阶段:CoT 监督微调
在第二阶段,研究人员收集了不同粒度的描述性文本,构建了推理生成指令数据。
这些数据包括粗粒度的描述作为答案内容,以及细粒度的描述作为推理内容。
通过监督微调,模型能够学习到如何根据指令生成具有逻辑推理的文本内容。
这一阶段的训练数据还包括通过高性能文生图模型生成的高质量图像,以提升模型的生成质量。
第三阶段:推理生成策略优化(RGPO)
在第三阶段,MindOmni 引入了推理生成策略优化(RGPO)算法。
这一算法的核心思想是通过强化学习,让模型能够显式地生成逻辑推理链。研究人员构建了一个包含用户指令、目标提示和对应解释的纯文本训练数据集,并设计了一个推理生成导向的系统提示,引导模型生成推理内容。
RGPO 强化学习算法
受 DeepSeek-R1 启发宝利配资,研究人员提出了 RGPO 强化学习算法,通过明确生成逻辑思路链来增强模型的推理生成能力。
在部署过程中,策略模型 πΘ 首先为每个请求 q 采样 G 组结果 {oi}Gi=1 ,每组结果包含一个推理链 oiT 和一个对应的图像 oiI。
为了提高生成推理过程的质量,研究者引入了两种奖励函数来引导策略模型生成连贯有效的输出:
格式奖励评估思路链是否符合预期结构,如果内容包含在对应标签中,则返回 1,否则返回 0。
一致性奖励使用来自 CLIP 图像和文本编码器的余弦相似度来衡量生成图像与参考真实提示之间的语义对齐情况。然后,通过所有奖励值计算第 i 个输出的优势 Ai,公式如下:
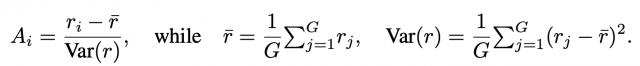
△训练流程概述:研究者提出了一个三阶段训练框架,包括预训练、基于指令的监督微调和基于 RGPO 的强化学习
在强化学习过程中,研究者引入了两种基于 KL 散度的蒸馏策略:DTKL 用于文本生成,DIKL 用于图像生成,以惩罚参考模型 π ref 与先前策略之间的较大偏差,从而促进更平滑的策略过渡,并降低遗忘先前学习知识的风险。
研究人员计算了 oi 的两个蒸馏函数,如下所示:
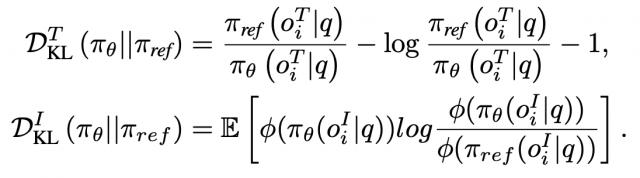
最后,通过最小化目标函数 来优化策略模型,如下所示 :
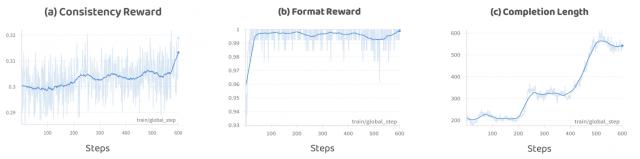
△RGPO 中不同 Metric 的曲线:" Completion Length "表示策略模型在部署过程中的输出长度;研究人员发现 CoT 长度和最终性能并不呈现正相关性实验结果 : 各大基准测试全面领先视觉理解和生成任务
通过广泛的实验,MindOmni 在多个多模态理解和生成基准测试中表现出色。
在图像理解方面,MindOmni 在 MMMU、MMBench 和 RealworldQA 等基准测试中取得了优异成绩。
与之前的统一模型相比,MindOmni 在 MMMU 上比 Janus-Pro 提升了 10.6%,在 MMBench 上比 MetaMorph 提升了 9.8%。
这些结果表明,MindOmni 在理解图像内容方面具有显著优势。
在文本到图像生成方面,MindOmni 在 GenEval 基准测试中取得了 83% 的总体分数,超越了其他统一模型。
此外,在 DPG-Bench 测试中,MindOmni 也表现出色,证明了其在生成任务中的强大能力。
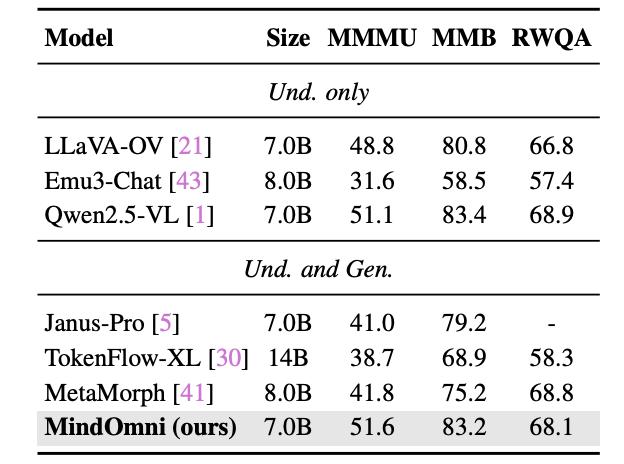
△视觉理解基准测试的性能比较:" Und. "和" Gen. "分别表示"理解"和"生成"
MindOmni 在推理生成任务中的表现尤为突出。
在 WISE 基准测试中,MindOmni 在文化知识、时空推理和自然科学等多个子类别中均超越了现有方法,取得了 0.71 的总体分数。
与生成型模型(如 FLUX 和 PixArt)以及统一模型(如 MetaQuery-XL)相比,MindOmni 在推理生成任务中展现了显著的优势。这主要得益于其联合理解 - 生成训练和基于 CoT 引导的强化学习。
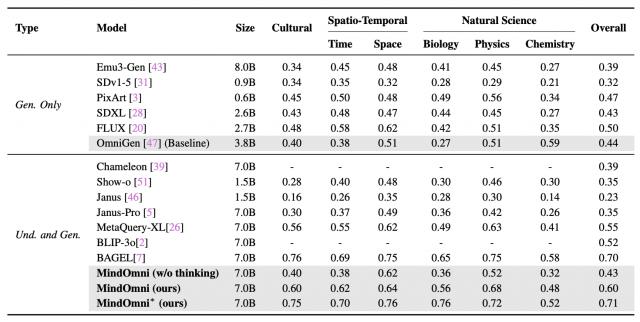
△与 WISE 基准上的最新模型进行比较定性结果
研究人员通过可视化不同模型的结果来展现 MindOmni 在推理生成方面的性能。
例如,在生成"具有(3 + 6)条命的动物"图像时,MindOmni 能够正确理解数学表达式,并生成与之相关的猫的图像,体现了其推理生成能力。
此外,在生成"悉尼歌剧院在纽约中午时的场景"图像时,MindOmni 能够考虑到悉尼和纽约的时差,并生成符合场景描述的图像。
同时 MindOmni 在图文多模态输入场景下也表现出色。更多可视化结果请参考论文及附录。
消融研究
为了验证训练策略的有效性,研究人员进行了广泛的消融实验。
实验结果表明,每个训练阶段对模型的性能有重要贡献。
例如,第一阶段的预训练为模型提供了基本的生成能力;第二阶段的监督微调显著提升了模型在 WISE 基准测试中的表现;而第三阶段的 RGPO 算法则进一步优化了模型的推理生成能力。
此外,消融实验还验证了不同连接器、KL 系数、组数和奖励策略对模型性能的影响。详细结果请参考研究论文。
论文链接:
https://arxiv.org/pdf/2505.13031
代码链接:
https://github.com/TencentARC/MindOmni
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
� � 点亮星标 � �
科技前沿进展每日见宝利配资
招财猫配资提示:文章来自网络,不代表本站观点。


沪深京指数
热点资讯